A Few extra details about Transformer
Recently I read a really nice article about Transformer in NLP. I want to write a summary and some details about the post as well as Transformer itself. A lot of pictures are directly from that post, definitely read the original post pleaes!

Input

Encoder (Self-Attention + Feed Forward Network)

Self-Attention


In reality, we can compute all z_i in parallel.

Multi-Head Self-Attention



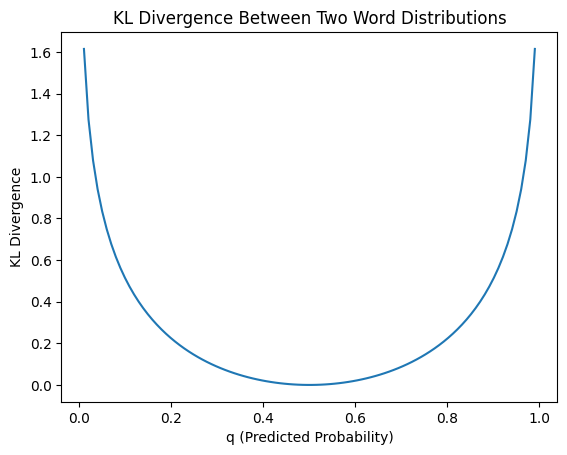
Positional Encoding (the hard-to-understand part)
First of all, the intuition is that Transformer does not encode position information. So we need a way to tell the model the position of each word in one sentence. This paper adds a positional encoding to the input:

Unfortunately, the excellent post explains this part in a wrong way. I found another post that tries to explain the positional encoding correctly with more details. The idea is each position takes a specific place in the frequency domain.


The proposed method has two immediate advantages:
- Each position vector is different and follows a specific trend.
- All values stay between [-1,1] and the summation within each vector is similar, this a very good property because the contribution of each word will not affect be the positional encoding.
Residual Connection
After every self-attention, the input and the output is added and layer-normalized.

Decoder
The output of the final encoder is transformed into a set of attention vectors K,V.

This is another part that I want to add details, let’s look at the code for PyTorch, that the attention of the decoder is a combination of input and output embeddings, the target words are embedded as well to compute the attention. This is one key difference compared with previous RNN models.

Loss
The output of the decoder is mapped back to the vocabulary space to compute the loss

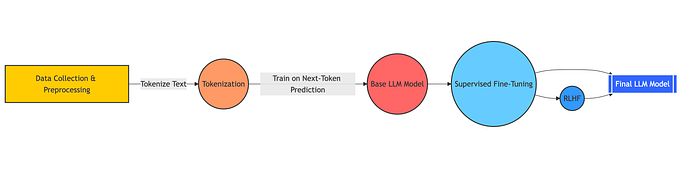
Summary
The encoder, decoder and the loss cover the main thing about Transformer, to summrize the thing in one figure: